
¿Qué es Hadoop en Big Data??
Resumen del artículo: Introducción a Hadoop y sus componentes
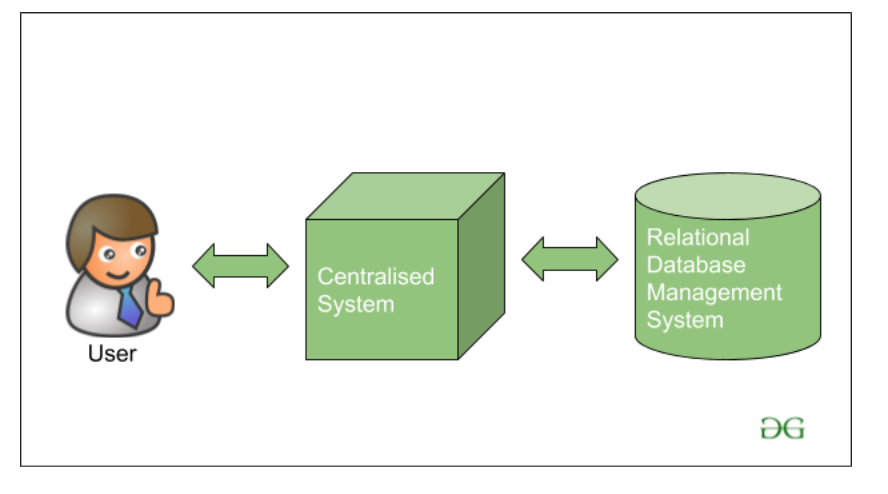
En este artículo, proporcionaremos una visión general de Hadoop, un marco de código abierto utilizado para administrar el almacenamiento y el procesamiento de grandes cantidades de datos. Hadoop utiliza almacenamiento distribuido y procesamiento paralelo para manejar grandes cargas de trabajo de análisis y análisis. Consiste en varios componentes, incluidos Apache Hive, Pig, Sqoop y Zookeeper, cada uno con diferentes funcionalidades. Hadoop se usa comúnmente en diversas aplicaciones, como recomendaciones personalizadas para clientes basados en datos de diferentes fuentes como la búsqueda de Google y los sitios web de redes sociales. También ofrece características integrales de seguridad que abarcan la administración, la autenticación/seguridad del perímetro, la autorización, la auditoría y la protección de datos. Las herramientas GIS, herramientas basadas en Java para sistemas de información geográfica, a menudo se usan junto con Hadoop. Hadoop se puede clasificar en diferentes tipos de grupos, como Big Data y MapReduce Clusters. La capa central de Hadoop comprende el sistema de archivos distribuidos de Hadoop (HDFS) para el almacenamiento, Hadoop MapReduce para su procesamiento y otro negociador de recursos (hilo) para la gestión de recursos. HDFS de Hadoop admite varios formatos de datos, incluidos datos estructurados, semiestructurados y no estructurados.
Puntos clave:
- Hadoop es un marco de código abierto para administrar grandes cantidades de datos en aplicaciones.
- Hadoop utiliza almacenamiento distribuido y procesamiento paralelo para manejar grandes cargas de trabajo de análisis y análisis.
- Los componentes principales de Hadoop incluyen Apache Hive, Pig, Sqoop y Zookeeper.
- Hadoop permite a los minoristas personalizar sus acciones en función de predicciones de fuentes como Google Search y Social Media.
- La seguridad integral en Hadoop abarca la administración, autenticación/seguridad perimetral, autorización, auditoría y protección de datos.
- Hadoop se usa a menudo con herramientas SIG para sistemas de información geográfica.
- Hadoop se puede clasificar en diferentes tipos de grupos, como Big Data y MapReduce Clusters.
- Hadoop consta de tres componentes centrales: Sistema de archivos distribuidos de Hadoop (HDFS), Hadoop MapReduce y otro negociador de recursos (hilo).
- HDFS de Hadoop admite varios formatos de datos, incluidos datos estructurados, semiestructurados y no estructurados.
Preguntas:
- ¿Qué es Hadoop y para qué se usa??
- ¿Puede proporcionar un ejemplo de cómo se usa Hadoop??
- ¿Cuáles son los cuatro componentes principales de Hadoop??
- ¿Cuál es la diferencia entre Big Data y Hadoop??
- ¿Cuáles son los cinco pilares de la seguridad de Hadoop??
- ¿Qué herramienta se usa comúnmente con Hadoop??
- ¿Cuáles son los dos tipos de grupos de Hadoop??
- ¿Cuáles son los tres componentes centrales de Hadoop??
- ¿Cuáles son los tres tipos de datos que admite Hadoop??
Hadoop es un marco de código abierto basado en Java que administra el almacenamiento y el procesamiento de grandes cantidades de datos para aplicaciones. Se utiliza para manejar grandes cargas de trabajo de datos y análisis a través de almacenamiento distribuido y procesamiento paralelo.
Por ejemplo, cuando un cliente intenta comprar un teléfono móvil, Hadoop puede sugerir artículos relacionados como portadas móviles y protectores de pantalla. También ayuda a los minoristas a personalizar sus acciones en función de predicciones de varias fuentes como la búsqueda de Google y los sitios web de redes sociales.
Los cuatro componentes principales de Hadoop son Apache Hive, Pig, Sqoop y Zookeeper. Cada componente realiza diferentes tareas dentro del ecosistema de Hadoop.
Hadoop es un marco que puede manejar grandes volúmenes de big data y procesarlos, mientras que Big Data se refiere al gran volumen de datos en sí, que puede estructurarse o no estructurarse.
Los cinco pilares de la seguridad de Hadoop son la administración, la autenticación/seguridad del perímetro, la autorización, la auditoría y la protección de datos. Estos pilares forman el marco para la seguridad integral en Hadoop.
Hadoop se usa comúnmente con herramientas SIG, que son herramientas basadas en Java para comprender la información geográfica.
Los dos tipos de grupos de Hadoop son grupos de big data y clústeres de MapReduce.
Los tres componentes centrales de Hadoop son el sistema de archivos distribuidos (HDF) para el almacenamiento, Hadoop MapReduce para su procesamiento y otro negociador de recursos (hilo) para la gestión de recursos.
Los HDFS de Hadoop pueden almacenar datos estructurados, semiestructurados y no estructurados.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] ¿Qué es Hadoop y para qué se usa para
Hadoop es un marco de código abierto basado en Java que administra el almacenamiento y el procesamiento de grandes cantidades de datos para aplicaciones. Hadoop utiliza almacenamiento distribuido y procesamiento paralelo para manejar los trabajos de Big Data y Analytics, dividiendo cargas de trabajo en cargas de trabajo más pequeñas que se pueden ejecutar al mismo tiempo.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] ¿Cuál es un ejemplo de Hadoop?
Por ejemplo, cuando un cliente intenta comprar un teléfono móvil, sugiere un cliente para la portada móvil, la protección de la pantalla. Además, Hadoop ayuda a los minoristas a personalizar sus acciones en función de las predicciones que provienen de diferentes fuentes, como la búsqueda de Google, los sitios web de redes sociales, etc.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] ¿Cuáles son los 4 componentes principales de Hadoop?
Hay varios componentes dentro del ecosistema de Hadoop, como Apache Hive, Pig, Sqoop y Zookeeper. Varias tareas de cada uno de estos componentes son diferentes.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] ¿Qué es diferente entre Big Data y Hadoop?
Definición: Hadoop es un tipo de marco que puede manejar el enorme volumen de big data y procesarlo, mientras que Big Data es solo un gran volumen de los datos que pueden estar en datos no estructurados y estructurados.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] ¿Cuáles son los 5 pilares de Hadoop?
Hortonworks cree firmemente que la seguridad efectiva de Hadoop depende de un enfoque holístico. Nuestro marco para la seguridad integral gira en torno a cinco pilares: administración, autenticación/ seguridad del perímetro, autorización, auditoría y protección de datos.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] ¿Qué herramienta se usa para Hadoop?
Hadoop se utiliza con herramientas GIS, que son una herramienta basada en Java disponible para comprender la información geográfica.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] ¿Cuáles son los 2 tipos de Hadoop?
Tipos de Hadoop Clustershadoop.data.Mapa reducido.data.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] ¿Cuáles son la capa de 3 núcleo de Hadoop?
Hay tres componentes de Hadoop: Hadoop HDFS – Hadoop Distributed File System (HDFS) es la unidad de almacenamiento. Hadoop MapReduce – Hadoop MapReduce es la unidad de procesamiento. Hadoop Yarn: otro negociador de recursos (hilo) es una unidad de gestión de recursos.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] Cuáles son los tres tipos de datos en Hadoop
Los HDFS de Hadoop pueden almacenar diferentes formatos de datos, como estructurado, semiestructurado y no estructurado.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] ¿Por qué necesitamos Hadoop en Big Data?
Hadoop es un marco de software de código abierto para almacenar datos y ejecutar aplicaciones en grupos de hardware de productos básicos. Proporciona un almacenamiento masivo para cualquier tipo de datos, una enorme potencia de procesamiento y la capacidad de manejar tareas o trabajos concurrentes prácticamente ilimitados.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] ¿Cuáles son las dos capas principales de Hadoop?
Hadoop Framework 1.2 Arquitectura de Hadoop Hay dos capas principales presentes en la arquitectura de Hadoop que ilustran en la Fig2. Son (a) capa de procesamiento/computación (MapReduce) (b) Capa de almacenamiento (sistema de archivos distribuido Hadoop).
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] ¿Qué idioma se usa para Hadoop?
Lenguaje de programación Java
El marco de Hadoop en sí se escribe principalmente en el lenguaje de programación Java, con algún código nativo en C y utilidades de línea de comandos escritas como scripts de shell.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] ¿Qué base de datos se usa en Hadoop?
Hadoop no es un tipo de base de datos, sino un ecosistema de software que permite la computación masivamente paralela. Es un habilitador de ciertos tipos de bases de datos distribuidas de NoSQL (como HBase), lo que puede permitir que los datos se extiendan a través de miles de servidores con poca reducción en el rendimiento.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] ¿Qué tipo de base de datos es Hadoop?
Es hadoop una base de datos Hadoop no es una base de datos, sino un marco de software de código abierto específicamente construido para manejar grandes volúmenes de datos estructurados y semiestructurados.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] ¿Cuál es la principal ventaja de Hadoop?
Hadoop es una plataforma de almacenamiento altamente escalable porque puede almacenar y distribuir conjuntos de datos muy grandes en cientos de servidores económicos que operan en paralelo. A diferencia de los sistemas de bases de datos relacionales tradicionales (RDBMS) que no pueden escalar para procesar grandes cantidades de datos.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] ¿Por qué Hadoop es mejor que SQL?
Quizás la mayor diferencia entre Hadoop y SQL es la forma en que estas herramientas administran e integran datos. SQL solo puede manejar conjuntos de datos limitados, como datos relacionales y luchas con conjuntos más complejos. Hadoop puede procesar grandes conjuntos de datos y datos no estructurados.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] ¿Qué tipo de datos se almacenan en Hadoop?
HDFS Big Data es datos organizados en el sistema de presentación HDFS. Como ahora sabemos, Hadoop es un marco que funciona mediante el uso de procesamiento paralelo y almacenamiento distribuido. Esto se puede usar para clasificar y almacenar big data, ya que no se puede almacenar de manera tradicional.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] Es Hadoop similar a SQL
Hadoop y SQL administran datos, pero de diferentes maneras. Hadoop es un marco de componentes de software, mientras que SQL es un lenguaje de programación. Para Big Data, ambas herramientas tienen pros y contras. Hadoop maneja conjuntos de datos más grandes, pero solo escribe datos una vez.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] ¿Es difícil aprender Hadoop?
Conocimiento SQL requerido para aprender Hadoop
A muchas personas les resulta difícil y son propensas al error mientras trabajan directamente con Java API’s. Esto también pone una limitación sobre el uso de Hadoop solo por los desarrolladores de Java. La programación de Hadoop también es más fácil para las personas con habilidades SQL, gracias a Pig and Hive.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] ¿Es Hadoop una base de datos SQL?
Hadoop y SQL administran datos, pero de diferentes maneras. Hadoop es un marco de componentes de software, mientras que SQL es un lenguaje de programación. Para Big Data, ambas herramientas tienen pros y contras. Hadoop maneja conjuntos de datos más grandes, pero solo escribe datos una vez.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] ¿Cuáles son las tres características de Hadoop?
Características de Hadoophadoop es de código abierto.Hadoop Cluster es muy escalable.Hadoop proporciona tolerancia a fallas.Hadoop proporciona alta disponibilidad.Hadoop es muy rentable.Hadoop es más rápido en el procesamiento de datos.Hadoop se basa en el concepto de localidad de datos.Hadoop proporciona viabilidad.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] ¿Qué idioma se usa en Hadoop?
Lenguaje de programación Java
El marco de Hadoop en sí se escribe principalmente en el lenguaje de programación Java, con algún código nativo en C y utilidades de línea de comandos escritas como scripts de shell.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] ¿Qué idioma es mejor para Hadoop?
Java
Java es el idioma detrás de Hadoop y es por eso que es crucial para el entusiasta de los big data aprender este idioma para depurar aplicaciones Hadoop.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] Que es mejor hadoop o sql
SQL funciona solo para datos estructurados, pero a diferencia de Hadoop, los datos se pueden escribir y leer varias veces. Hadoop se desarrolla para big data, por lo tanto, generalmente maneja los volúmenes de datos hasta terabytes y petabytes. SQL funciona mejor en bajos volúmenes de datos, generalmente en gigabytes.
[wPremark_icon icon = “QUOTE-TE-SOT-2-SOLID” Width = “Width =” “” 32 “altura =” 32 “] Se requiere codificación para Hadoop
Se requiere la codificación para Hadoop Hadoop es un marco de código abierto codificado por Java, pero trabajar con él requiere muy poco conocimiento de los lenguajes de programación. El software de Hadoop se crea mediante el uso de la codificación de Java.

